面对浏览器,我们经常需要考虑一些性能的问题,除了让用户提高带宽,我们还需要通过缓存一些文件来提高用户体验。浏览器的缓存即是HTTP缓存,我们打开浏览器时总需要与远程服务器做交互,如果服务器允许的话,浏览器首次访问网站时会把成功的请求结果拦截下来并存储在内存或硬盘上,以便下次访问时快速获取。零零散散看过许多HTTP缓存的文章,所以这次想梳理一下脉络和自己动手模拟一下服务器看看我们可以如何指控浏览器缓存我们的文件。
DEMO
学习过程中做了一个小demo模拟缓存过程,可以在https://github.com/abigaleypc/express-cache.git中查看源码。
强缓存 与 协商缓存
HTTP缓存可以分为强缓存 与 协商缓存两大类。强缓存是当我们发起一个HTTP请求时,前端不会与服务器做交互,而是根据上一次设置的缓存期限,未过期时则不再向后端做请求,即使文件已经被更新了我们也无法获取。而协商缓存则需要与服务器做一个交互,当服务器告诉我们上次的缓存并未做修改时,后端则不返回我们需要的文件,否则返回最新文件。
强缓存
强缓存包含Expires 与 cache-control
Expires
表示存在时间,允许客户端在这个时间之前不去检查(发请求),例如:Expires: Wed, 21 Oct 2015 07:28:00 GMT
可采用两种方法对Expires进行设置:
页面标签中设置
1< META HTTP-EQUIV="Expires" VALUE="May 31,2001 13:30:15" >后端设置
1Response.Expires=时间(单位:分)来启用缓存。 // 另一种方式 Response.AddHeader("expires","utc时刻")
以上时间表示消息发送的时间,时间的描述格式由rfc822定义。例如,Web服务器告诉浏览器在2018-04-28 03:30:01这个时间点之前,可以使用缓存文件。发送请求的时间是2018-04-28 03:25:01,即缓存5分钟。
理解cache-control
强缓存 - 体验max-age
“max-age”指令指定从请求的时间开始,允许获取的响应被重用的最长时间(单位:秒)。如果还有一个 设置了 “max-age” 或者 “s-max-age” 指令的Cache-Control响应头,那么 Expires 头就会被忽略。
下面做一个测试max-age的实验,打开GitHub的项目并npm start ,测试之前请打开控制台,将浏览器控制台中的Disable cache关闭。如下图
Step1: 在入口文件
app.js中设置最大缓存时间,如下:123456app.use("/public",express.static("public", {maxAge: "1d"}));Step2: 将
/public下的静态文件最大缓存时间设为一天,现在在/public下的main.js写了一段更新页面文本的代码1234window.onload = function() {let name = document.getElementById("name");name.innerText = "abigale";};Step3: 第一次打开浏览器并打开控制台,点击
max-age菜单,采用max-age做缓存:浏览器查找缓存文件的顺序为 memory - disk - 网络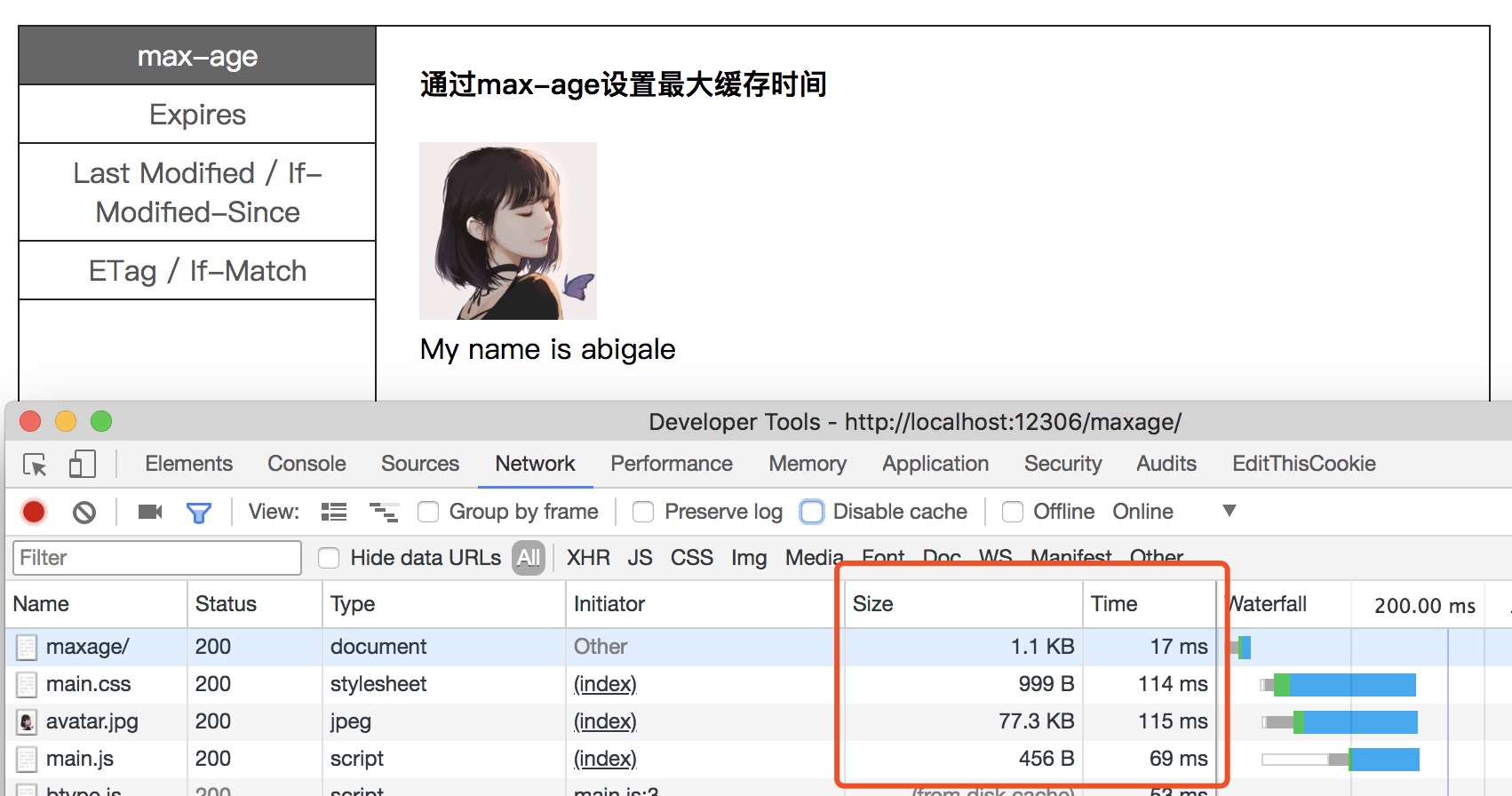
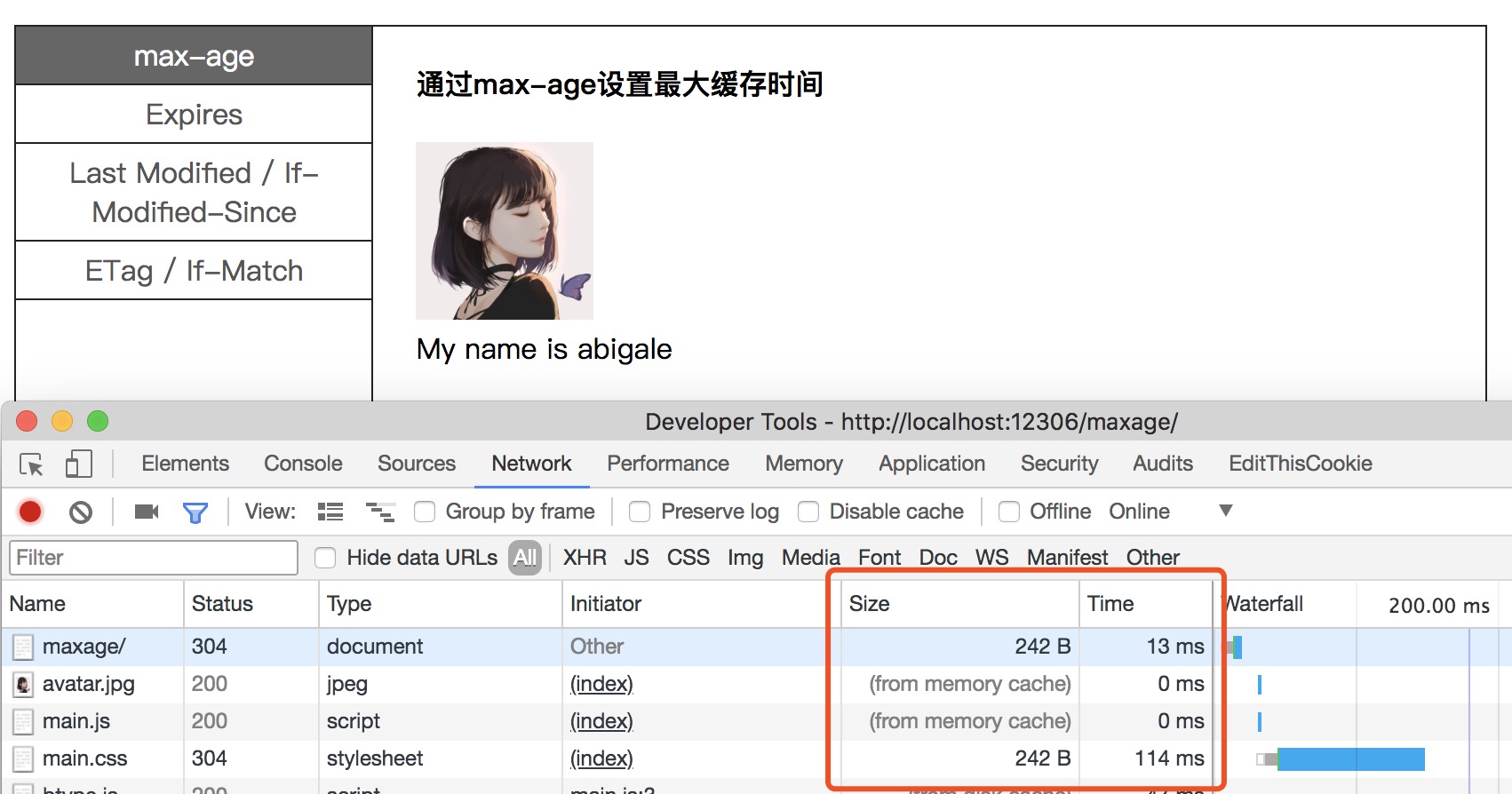
Step4: 刷新页面:缓存优先从memory查找,如查找得到则采用memory中文件
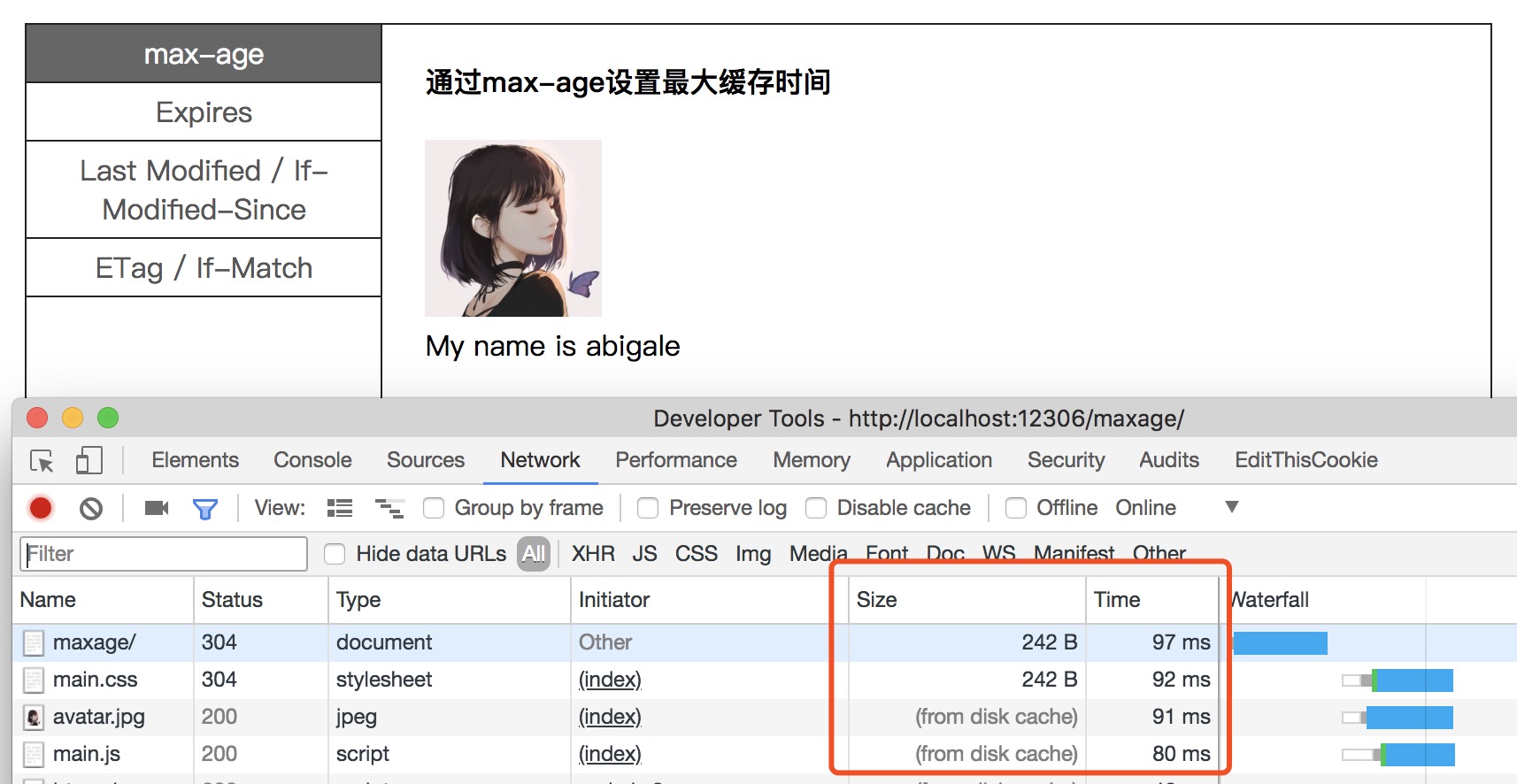
Step5: 重新打开页面:memory若无缓存,则从disk查找
Step6: 修改
/public/main.js1234window.onload = function() {let name = document.getElementById("name");name.innerText = "AbigaleYu";};无论是刷新页面访问还是重新打开页面访问,结果与
Step4Step5一样,name并没有更新为AbigaleYu。这是因为强缓存在缓存时间内并不会去获取新文件,而是采用缓存文件
该缓存策略弊端: 当设定时间内更新文件了,浏览器并不知道。
其他value
cache-control 下还有其他几个常用的value
- no-cache: 表示每次请求都需要与服务器确认一次,这种情况一般带有ETag,当服务器端验证无修改时,则从缓存中取文件,服务器无需返回文件。
- no-store: 表示无论如何都不允许客户端做缓存,每次凑需要做一次完整的请求和完整的响应。
- public:如果响应被标记为“public”,则即使它有关联的 HTTP 身份验证,甚至响应状态代码通常无法缓存,也可以缓存响应。大多数情况下,“public”不是必需的,因为明确的缓存信息(例如“max-age”)已表示响应是可以缓存的。我们有时可以在memory,disk,路由等找到缓存就是因为这是public的设置
- private:不允许任何中间缓存对其进行缓存,只能最终用户做缓存
举一些例子
| 缓存设置 | 表现 |
|---|---|
| max-age=86400 | 浏览器以及任何中间缓存均可将响应(如果是“public”响应)缓存长达 1 天(60 秒 x 60 分钟 x 24 小时)。 |
| max-age=86400 | 浏览器以及任何中间缓存均可将响应(如果是“public”响应)缓存长达 1 天(60 秒 x 60 分钟 x 24 小时)。 |
| private, max-age=600 | 客户端的浏览器只能将响应缓存最长 10 分钟(60 秒 x 10 分钟)。 |
| no-store | 不允许缓存响应,每次请求都必须完整获取。 |
引申问题:from memory cache 与 from disk cache 的区别
浏览器访问页面时,查找静态文件首先会从缓存中读取,缓存分为两种,内存缓存与硬盘缓存。查找文件的顺序为:memory -> disk -> 服务器。内存缓存是在kill进程时删除,即关闭浏览器时内存缓存消失,而硬盘缓存则是即使关闭浏览器也仍然存在。当我们首次访问页面,需要从服务器获取资源,将可缓存的文件缓存在内存与硬盘,当刷新页面时(这种情况没有关闭浏览器)则从内存缓存中读取,我们可以在上面的截图看到from memory cache的所需要的时间为0,这是最快的读取文件方式,当我们重新开一个页面时,也就是已经kill这个进程,内存缓存已经消失了,这时候就从硬件缓存获取,而当我们手动在浏览器清除缓存时,下次访问就只能再去服务器拉取文件了。但有一点可以从上面图中看到,并不是从硬盘获取缓存的时间一定比从网络获取的时间短,示例中的时间是更长的,这取决于网络状态和文件大小等因素,从缓存获取有利有弊,当网络较差或者文件较大时,从硬盘缓存获取可以给用户较好的体验。
协商缓存
Last-Modified 与 If-Modify-since
- Last-Modified 标示这个响应资源的最后修改时间。web 服务器在响应请求时,告诉浏览器资源的最后修改时间
- If-Modify-since 再次向服务器请求时带上,如果资源已修改,返回 HTTP 200,未被修改,返回 HTTP 304
DEMO : 依然是GitHub的源码。可切换到菜单 Last Modified / If-Modified-Since 查看
Step1: 在
app.js入口文件中,我们通过将 Last-Modified 的头设置为操作系统上该文件的上次修改日期来控制缓存1234567app.use("/lastModified",express.static("public/lastModified", {lastModified: true,setHeaders: setCustomCacheControl}));Step2: 在路径为
./public/lastModified/main.js的文件中,读取文件response header中的 Last-modified 展示出来
|
|
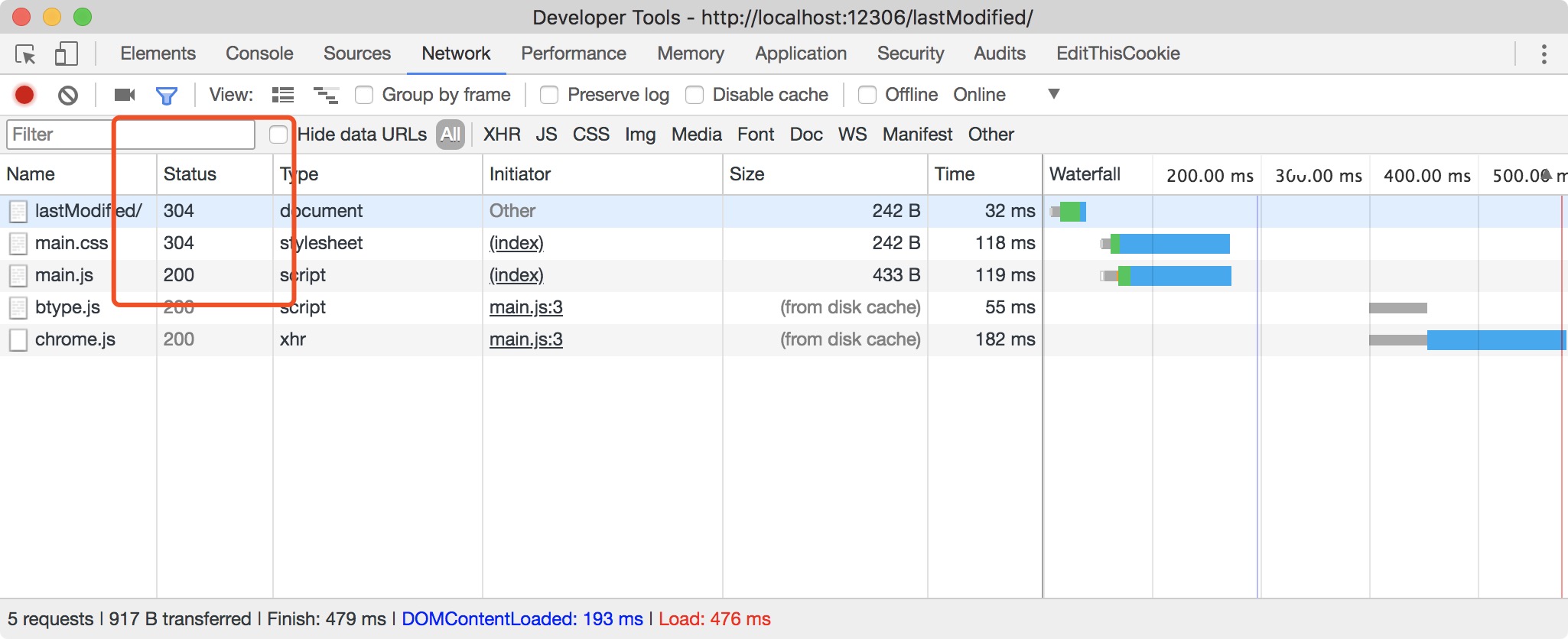
Step3: 点击菜单
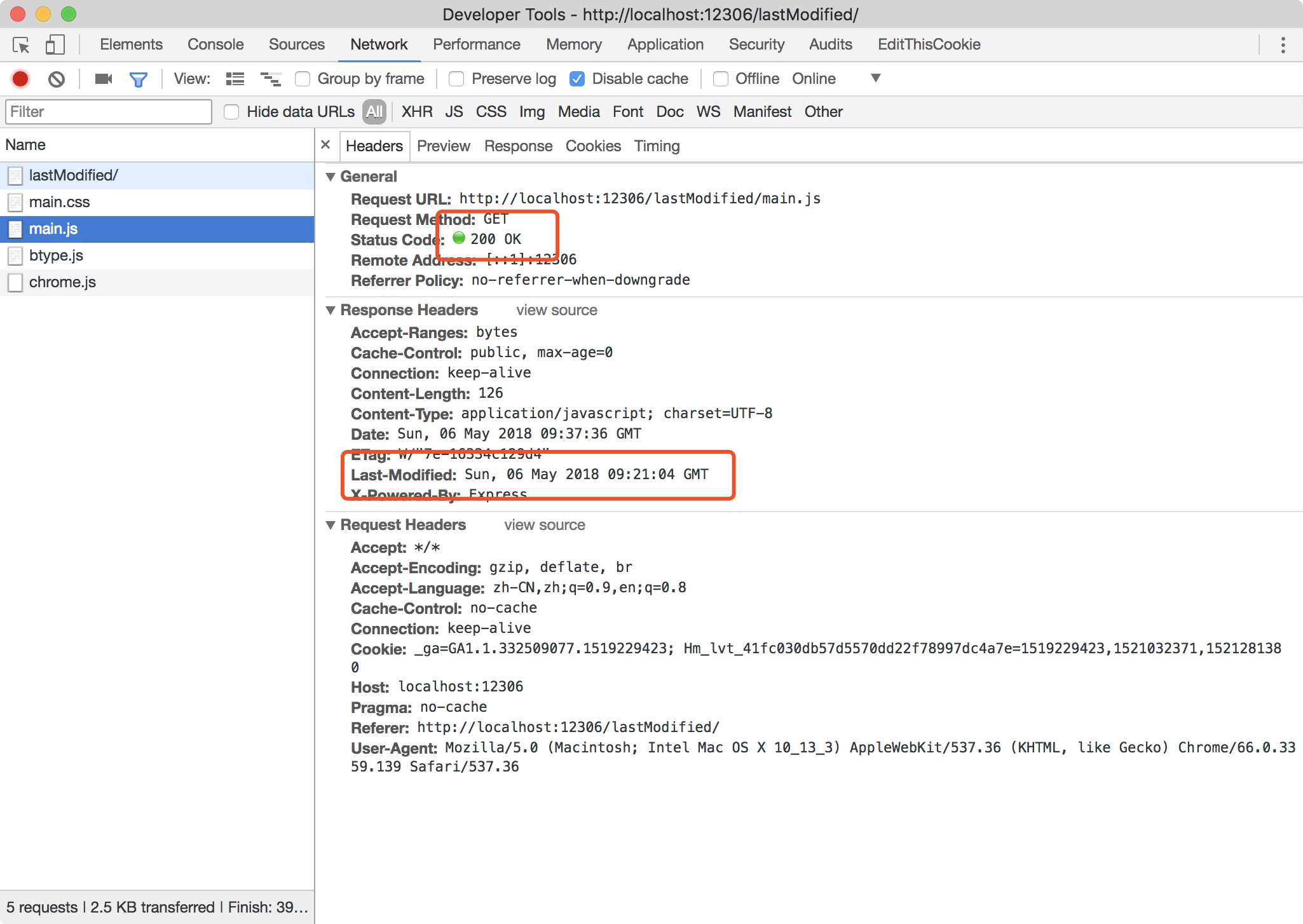
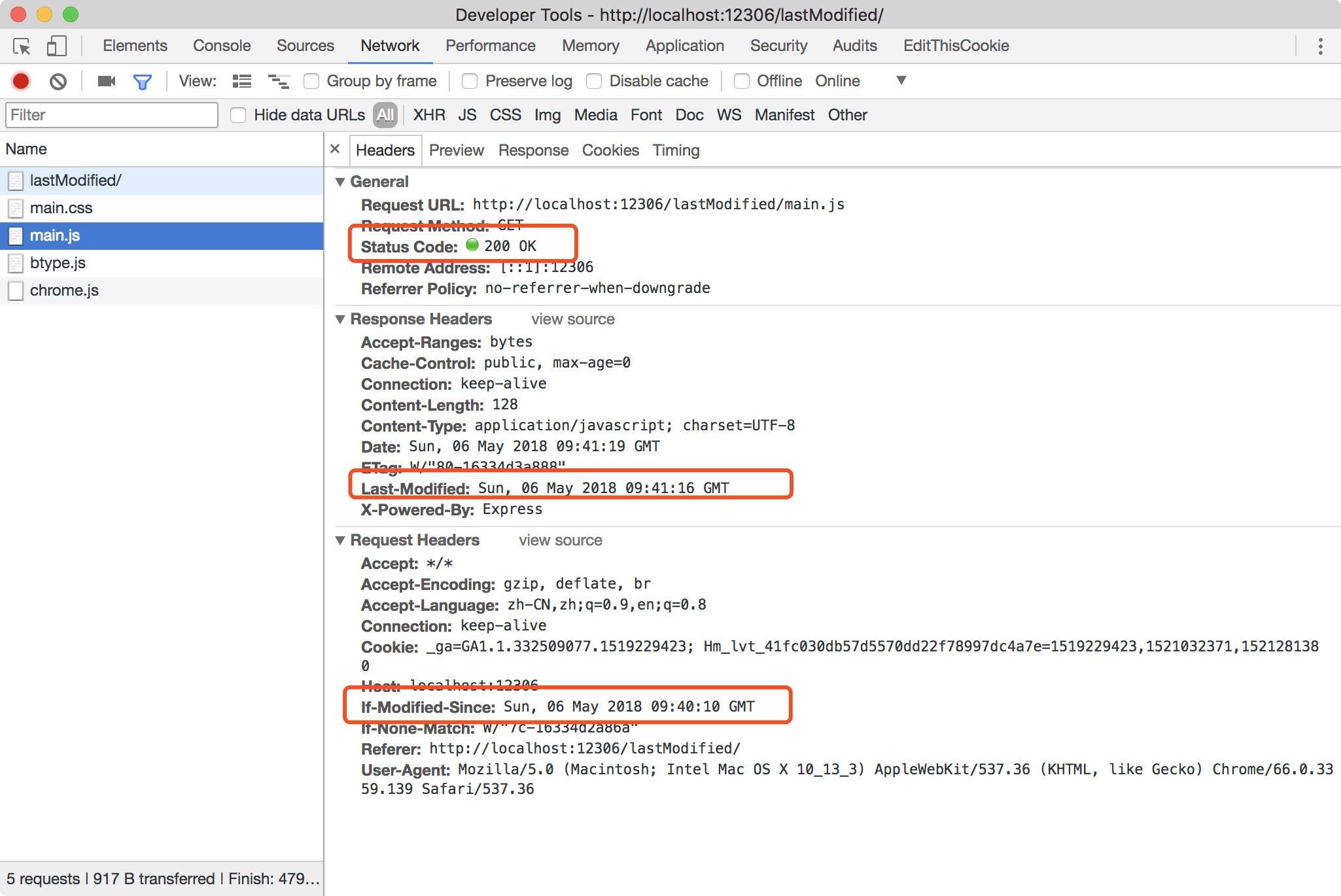
Last Modified / If-Modified-Since,第一次请求状态码是意料中的200,但可以看到响应头response header多了Last-modified 记录我们最后修改文件的时间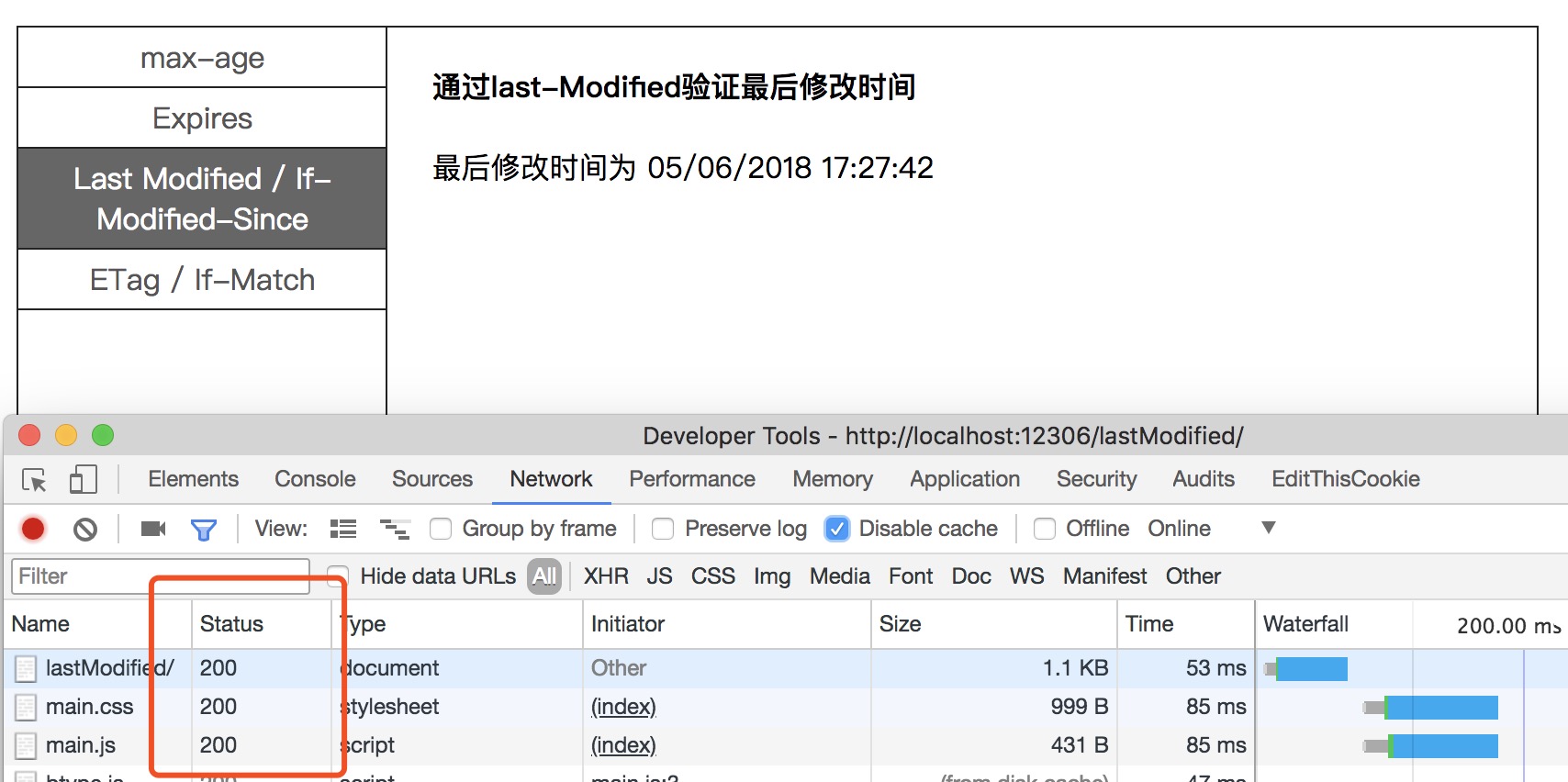
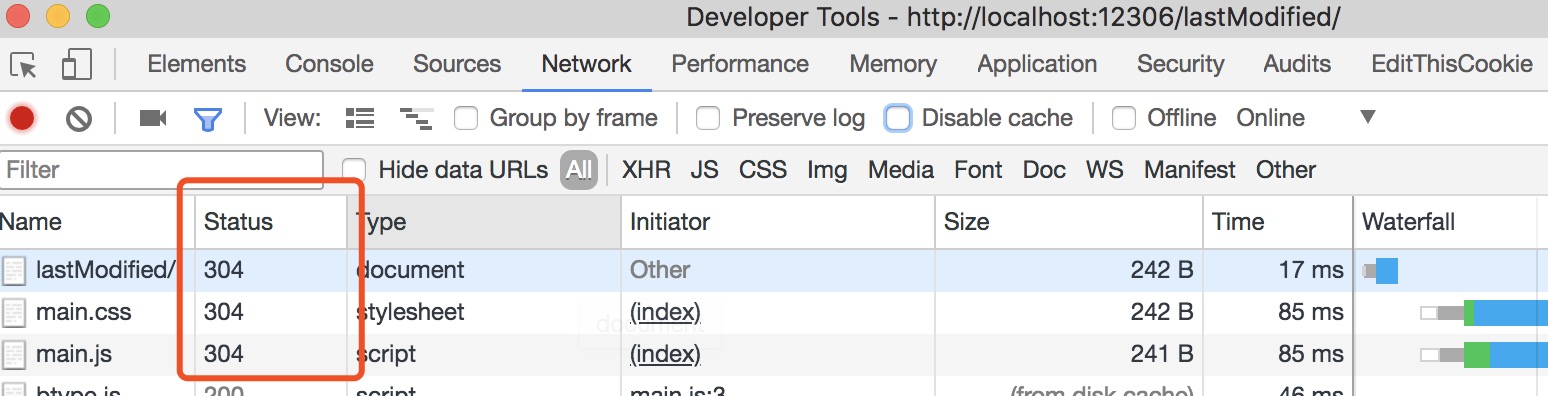
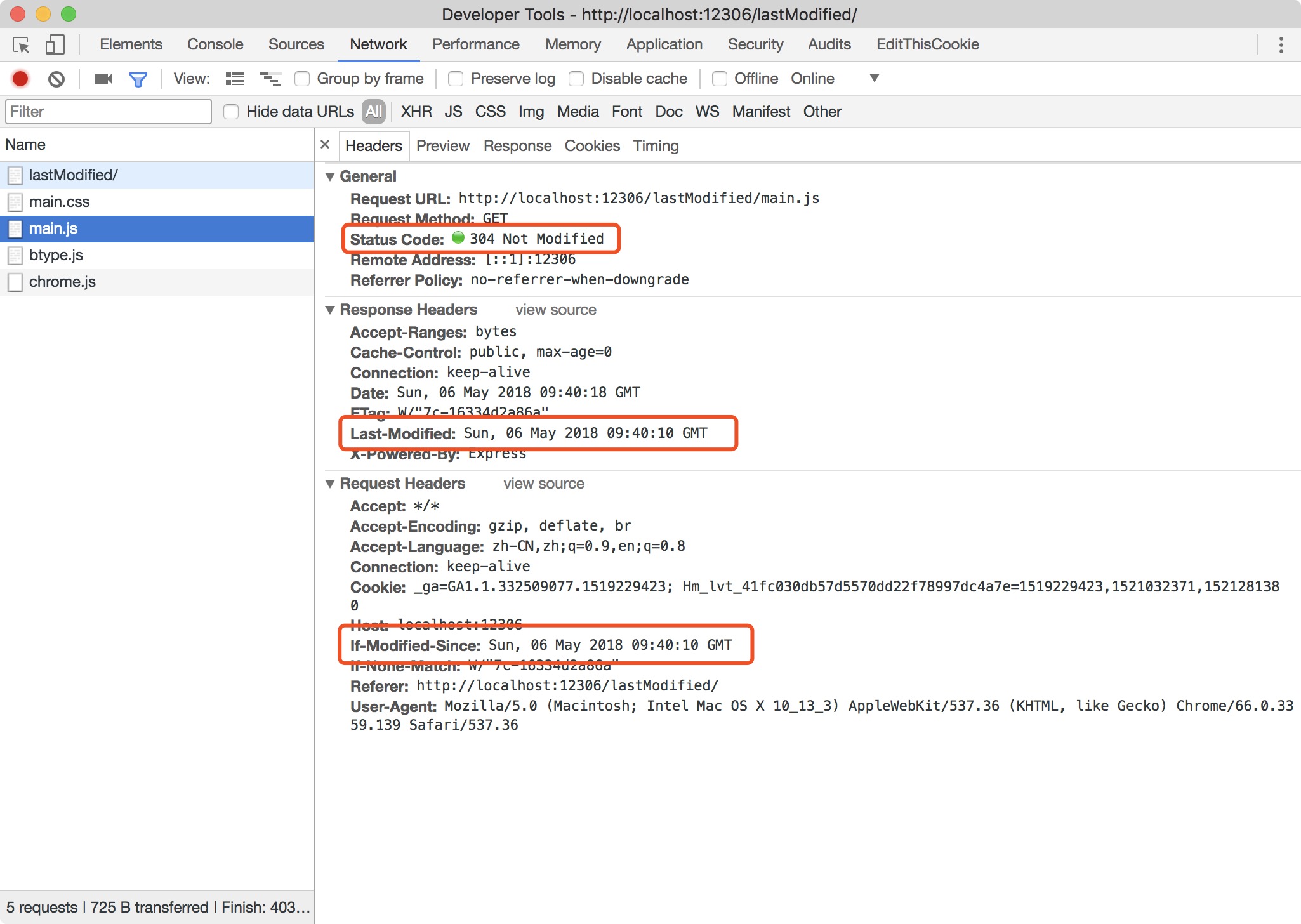
Step4: 再次刷新页面时,状态码更新为304(Not Modified),但不同与max-age,此处的304虽然是文件并未被修改,但依然需要相似的请求时间,这是因为协商缓存需要向服务器咨询文件是否被更新,而且可以看到该请求中request header 多了 If-Modified-Since 字段,这就是告诉浏览器上次文件的修改时间。可以看到上次修改时间 If-Modified-Since 与 响应头 response header 中 Last-modified 是一致的,因此返回文件未被修改。
Step5: 修改main.js中的内容,并刷新页面,这次可以看到main.js的请求不是返回304,而是200,展开main.js请求,也可以看到request header 中上次修改时间 If-Modified-Since 与 响应头 response header 中 Last-modified 是不一致的,因为我们需要获取到最新文件而不是使用缓存文件。
ETag 和 If-None-Match
- ETag 告诉浏览器当前资源在服务器的唯一标识
- If-None-Match 再次向服务器请求时带上,如果资源已修改,返回 HTTP 200,未被修改,返回 HTTP 304
总结
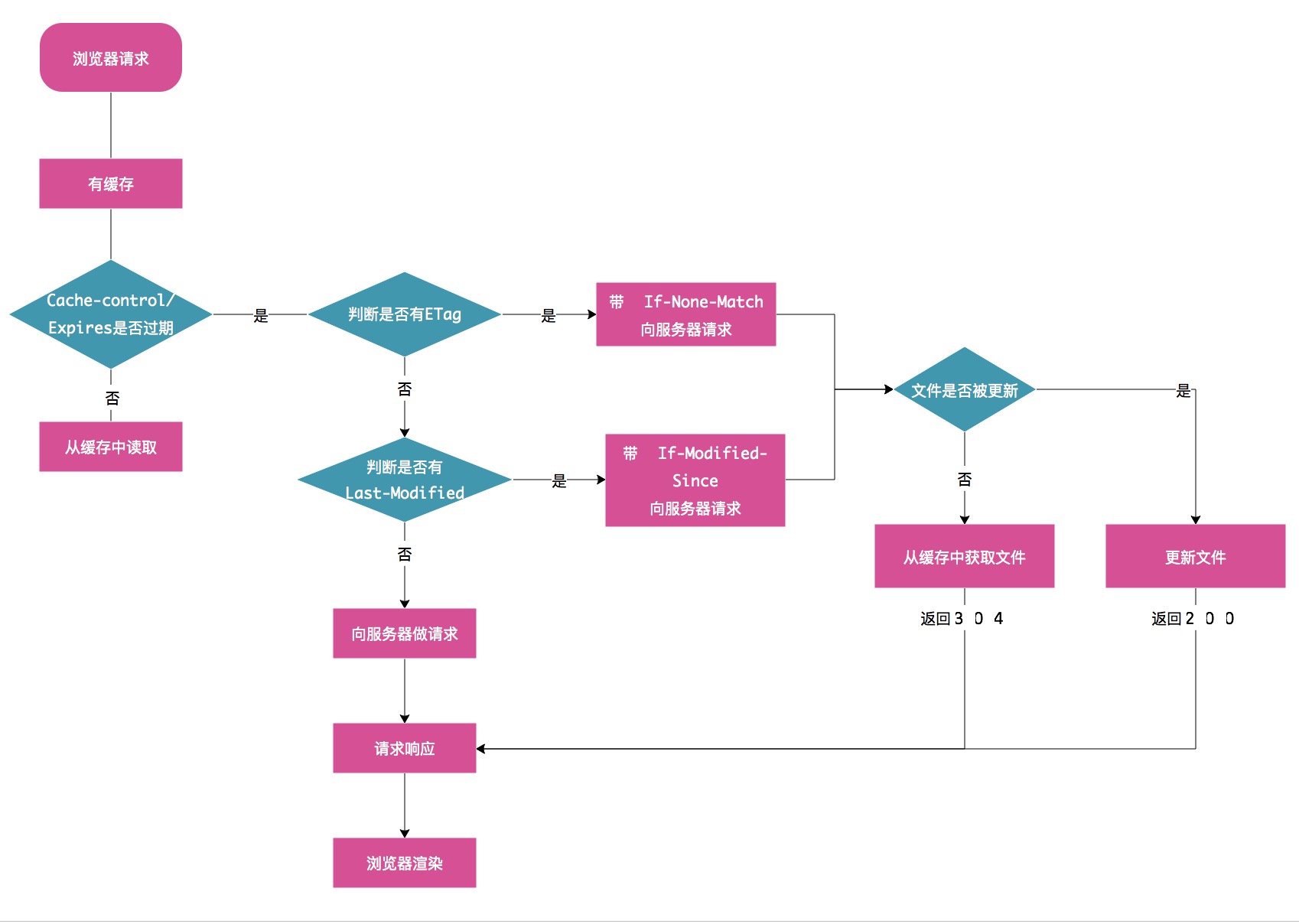
浏览器获取文件的过程如下: