跨域
手写一个JSONP的实现
|
|
|
|
跨域的方式?
- 客户端
- jsonp:原理:通过
<script>标签请求,再用callback函数返回需要的字段。因为Web页面上调用js文件时则不受是否跨域的影响 - document.domain:通过修改该字段来跨子域,但只适用于不同子域的框架间的交互。
- window.name:这种方法与document.domain 方法相比,放宽了域名后缀要相同的限制,可以从任意页面获取 string 类型的数据
- postMessage
- jsonp:原理:通过
- 服务端
- CORS: 服务器 在响应头中设置相应的选项(Access-Control-Allow-Origin 和 Access-Control-Allow-Credentials)
- 代理
- Nginx
jsonp安全漏洞
xss:callback里传入
callback=<script>xx<script>解决办法:
Content-Type: application / json只能传入jsoncsrf:json劫持
123456<script>function wooyun(v){alert(v.username);}</script><script src="http://js.login.360.cn/?o=sso&m=info&func=wooyun"></script>这个是在乌云网上报告的一个攻击例子( WooYun-2012-11284 )
http://www.wooyun.org/bug.php?action=view&id=11284当被攻击者在登陆 360 网站的情况下访问了该网页时,那么用户的隐私数据(如用户名,邮箱等)可能被攻击者劫持。
参考:JSONP 安全攻防技术
缓存
HTTP协议缓存的实现
以下是后端控制的缓存
- 强缓存的方法:expire 和 cache-control
- 协商缓存的方法:last-modified/Last-modified-since 和 ETag 和 If-None-Match
静态文件的缓存/如果服务器端更新脚本,如何保证客户端不受缓存机制影响,实时更新脚本
- 在文件后加版本号 如xxx.js?v=1.1.1
- 拼接文件名 如 xxx111111.js
前端存储
对比
- 存储量
- 存储类型
- 使用方式
- 数据的生命期
- 与服务器端通信
- 优点
- 缺点
存储量
- cookie: 4KB
- sessionStorage: 一般为5MB
- localStorage: 一般为5MB
存储类型
- cookie: 字符串
- sessionStorage: 键值对
- localStorage: 键值对
使用方式
- cookie: 获取 cookie 可以直接使用
document.cookie,但是获取到的 cookie 是一个字符串,它包含了 cookie 中存储的所有数据,形式如"key1=value1; key2=value2" - sessionStorage: 普通对象非常相似,可以直接通过中括号
sessionStorage[‘key’]的方式添加和获取数据,也可以通过点语法sessionStorage.key的方式进行操作,sessionStorage 也有自己的 api 用于操作数据。或者sessionStorage.setItem('key', 'value');var data = sessionStorage.getItem('key') - localStorage: 同上
数据的生命期
- cookie: 一般由服务器生成,可设置失效时间。如果在浏览器端生成Cookie,默认是关闭浏览器后失效
- sessionStorage: 仅在当前会话下有效,关闭页面或浏览器后被清除
- localStorage: 除非被清除,否则永久保存
与服务器端通信
- cookie: 每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题
- sessionStorage: 仅在客户端(即浏览器)中保存,不参与和服务器的通信
- localStorage: 同上
优点
- cookie: 有大量的库可供我们更方便快捷得操作 cookie ,如 jQuery.cookie.js
- sessionStorage:
- 存储的数据不会被自动随着请求被发送到服务端
- 可存储的数据大小相比 cookie 来说大了很多,但是每个浏览器都不同,所以没有一个统一的值。
- localStorage:
- 数据存储量大;
- 不会被发送到服务端;
- 持久化本地存储,除非手动删除,否则一直存在;
- 在同一个域下,所有窗口共享其中存储的数据 (sessionStorage则不可)
缺点
- cookie: 如
"key1=value1; key2=value2"这样的字符串无法通过 JSON.parse() 转换为 json 格式的数据,需要通过正则表达式的方式将所需要的值匹配出来 - sessionStorage:
- sessionStorage 中只能够保存字符串类型的数据,所以在保存非字符串类型的数据时,一定要先将其转换成字符串,比如图片可以转换成 base64 字符串后保存,对象可使用 JSON.stringify() 转为字符串后存储,甚至可以存储一段 js 脚本
- 其中所存储的数据的生命周期与 session 类似,即只存在于一个会话周期内,当浏览器关闭或标签页关闭时,数据即会被删除(前进和后退并不会影响到数据,因为还在当前的会话中),这就导致了即便是同一个网站,但在不同的标签页和窗口内,也无法共享其中存储的数据
- localStorage:
- 只能够保存字符串类型的数据,所以在保存非字符串类型的数据时,一定要先将其转换成字符串,比如图片可以转换成 base64 字符串后保存,对象可使用 JSON.stringify() 转为字符串后存储,甚至可以存储一段 js 脚本
状态码
1xx: 信息
- 100 Continue 服务器仅接收到部分请求,但是一旦服务器并没有拒绝该请求,客户端应该继续发送其余的请求。
- 101 Switching Protocols 服务器转换协议:服务器将遵从客户的请求转换到另外一种协议。
2xx: 成功
- 200 OK 请求成功(其后是对GET和POST请求的应答文档。)
- 201 Created 请求被创建完成,同时新的资源被创建。
- 202 Accepted 供处理的请求已被接受,但是处理未完成。
- 203 Non-authoritative Information 文档已经正常地返回,但一些应答头可能不正确,因为使用的是文档的拷贝。
- 204 No Content 没有新文档。浏览器应该继续显示原来的文档。如果用户定期地刷新页面,而Servlet可以确定用户文档足够新,这个状态代码是很有用的。
- 205 Reset Content 没有新文档。但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容。
- 206 Partial Content 客户发送了一个带有Range头的GET请求,服务器完成了它。
3xx: 重定向
- 300 Multiple Choices 多重选择。链接列表。用户可以选择某链接到达目的地。最多允许五个地址。
- 301 Moved Permanently 所请求的页面已经转移至新的url。
- 302 Found 所请求的页面已经临时转移至新的url。
- 303 See Other 所请求的页面可在别的url下被找到。
- 304 Not Modified 未按预期修改文档。客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。
- 305 Use Proxy 客户请求的文档应该通过Location头所指明的代理服务器提取。
- 306 Unused 此代码被用于前一版本。目前已不再使用,但是代码依然被保留。
- 307 Temporary Redirect 被请求的页面已经临时移至新的url。
4xx: 客户端错误
- 400 Bad Request 服务器未能理解请求。
- 401 Unauthorized 被请求的页面需要用户名和密码。
- 402 Payment Required 此代码尚无法使用。
- 403 Forbidden 对被请求页面的访问被禁止。
- 404 Not Found 服务器无法找到被请求的页面。
- 405 Method Not Allowed 请求中指定的方法不被允许。
5xx: 服务器错误
- 500 Internal Server Error 请求未完成。服务器遇到不可预知的情况。
- 501 Not Implemented 请求未完成。服务器不支持所请求的功能。
- 502 Bad Gateway 请求未完成。服务器从上游服务器收到一个无效的响应。
- 503 Service Unavailable 请求未完成。服务器临时过载或当机。
- 504 Gateway Timeout 网关超时。
- 505 HTTP Version Not Supported 服务器不支持请求中指明的HTTP协议版本。
Ajax
什么是 Ajax,它们的优缺点。
Ajax 是异步 JavaScript 和 XML,用于在 Web 页面中实现异步数据交互。
Ajax 优点
- 可以使得页面不重载全部内容的情况下加载局部内容,降低数据传输量
- 避免用户不断刷新或者跳转页面,提高用户体验
Ajax 缺点
- 对搜索引擎不友好 (解释:因为 ajax 内容是动态爬取的,而爬虫只能爬页面一开始的 HTML)
- 要实现 ajax 下的前后退功能成本较大(AJAX 干掉了 Back 和 History 功能,即对浏览器机制的破坏)
- 可能造成请求数的增加(增大网络数据的流量是因为要发很多次请求才能把页面渲染出来)
- 跨域问题限制
ajax 如何实现
首先实现 ajax 之前必须要创建一个 XMLHttpRequest 对象的 –> open –> send
- GET
|
|
- POST
|
|
Ajax 状态
readyState 属性 状态 有 5 个可取值: 0 = 未初始化,1 = 启动, 2 = 发送,3 = 接收,4 = 完成
Ajax 同步和异步的区别:
- 同步:提交请求 -> 等待服务器处理 -> 处理完毕返回,这个期间客户端浏览器不能干任何事
- 异步:请求通过事件触发 -> 服务器处理(这是浏览器仍然可以作其他事情)-> 处理完毕
ajax.open 方法中,第 3 个参数是设同步或者异步。
手写一个Ajax的Promise封装
|
|
GET和POST
GET和POST的区别
- GET用于信息获取,而且应该是安全的和幂等的。(幂等就是每次请求结果都一样);POST表示可能修改变服务器上的资源的请求。Get是向服务器发索取数据的一种请求,而Post是向服务器提交数据的一种请求
- GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连;POST把提交的数据则放置在是HTTP包的包体中。
- GET方式提交的数据最多只能是1024字节;POST是没有大小限制的,HTTP协议规范也没有进行大小限制
- GET能被缓存,POST不能缓存。
URL到渲染
浏览器从URL到页面渲染经历了哪些?
- 域名解析成IP
- 找到IP对应服务器
- 发送HTTP请求
- 响应HTTP请求
- 渲染页面
域名解析IP寻找路径
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
一个完整的HTTP请求过程,通常有下面7个步骤
- 建立TCP连接
- Web浏览器向Web服务器发送请求命令
- Web浏览器发送请求头信息
- Web服务器- 应答
- Web服务器- 发送响应头信息
- Web服务器- 向浏览器发送数据
- Web服务器- 关闭TCP连接
> 可以根据自己擅长的领域自由发挥,从URL规范、HTTP协议、DNS、CDN、数据查询、浏览器流式解析、CSS规则构建、layout、paint、onload/domready、JS执行、JS API绑定等等;
详细解释
- 浏览器会开启一个线程来处理这个请求,对 URL 分析判断,如果是 http 协议就按照 web 方式来处理;
- 调用浏览器内核中的对应方法,比如 WebView 中的 loadUrl 方法;
- 通过 DNS 解析获取网址的 IP 地址,设置 UA 等信息发出第二个 GET 请求;
- 进行 HTTP 协议会话,客户端发送报头(请求报头);
- 进入到 web 服务器上的 Web Server,如 Apache、Tomcat、Node.js 等服务器;
- 进入部署好的后端应用,如 PHP、Java、JavaScript、Python 等,找到对应的请求处理;
- 处理结束回馈报头,此处如果浏览器访问过,缓存上有对应资源,会与服务器最后修改事件对比,一致则返回304;
- 浏览器开始下载 html 文档(响应报头,状态码200),同时使用缓存;
- 文档树建立,根据标记请求所需指定 MIME 类型的文件(比如css、js),同时设置 cookie;
- 页面开始渲染 DOM ,JS 根据 DOM API 操作 DOM ,执行事件绑定等,页面显示完成;
概要
- 浏览器根据请求的 URL 交给 DNS 域名解析,找到真实 IP ,向服务器发起请求;
- 服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、CSS、JS、image等);
- 浏览器对加载到的资源(HTML、CSS、JS等)进行语法解析,建立相应的内部数据结构(如 HTML 的 DOM );
载入解析到的资源文件,渲染页面,完成。
如何渲染页面
- 请求HTML文件解析成DOM树
- 关联到CSS解析成CSSOM
- DOM和CSSOM构造Render Tree
- 边计算边绘制
Method
Http协议中有那些请求方式?
- GET: 用于请求访问已经被URI(统一资源标识符)识别的资源,可以通过URL传参给服务器
- POST:用于传输信息给服务器,主要功能与GET方法类似,但一般推荐使用POST方式。
- PUT: PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样
- HEAD: 获得报文首部,与GET方法类似,只是不返回报文主体,一般用于验证URI是否有效。
- DELETE:删除文件,与PUT方法相反,删除对应URI位置的文件。
- OPTIONS:查询相应URI支持的HTTP方法。
HTTPS原理
原理
- HTTPS其实是有两部分组成:HTTP + SSL / TLS
- 服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书- 可以自己制作
- 也可以向组织申请
区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面(startssl就是个不错的选择,有1年的免费服务)
- 证书:公钥 和 私钥
- 私钥存于服务端 和 客户端
- 公钥用于两端之间传送信息。比如有参数,则参数+公钥传送
HTTPS 过程
包括域名解析IP 三次握手 后 建立TCP连接 然后SSL握手过程 TCP连接关闭
HTTPS - SSL握手过程
- 客户端首先会将自己支持的加密算法,打个包告诉服务器端
- 服务器端从客户端发来的加密算法中,选出一组加密算法和HASH算法。并将自己的身份信息以证书的形式发回给客户端。而证书中包含了网站的地址,加密用的公钥,以及证书的颁发机构等;
- 客户端收到了服务器发来的数据包后
- 验证一下证书是否合法
- 合法的话,客户端就会随机产生一串序列号,+ 公钥
- 一串序列号 + 加密算法 生成 消息校验值 发给服务端
- 服务端接收后
- 使用私钥解密 刚才上一步的2 (产生一串序列号,+ 公钥 ) 得到序列号
- 使用序列号 加密后看是否与上一步的3 一致
- 序列号 + 选择的加密算法,加密一段握手消息,发还给客户端。同时HASH值也带上。
- 客户端收到服务器端的消息后,接着做这么几件事情:
- 计算HASH值是否与发回的消息一致
- 检查消息是否为握手消息
HTTP的缺点与HTTPS
- 通信使用明文不加密,内容可能被窃听
- 不验证通信方身份,可能遭到伪装
无法验证报文完整性,可能被篡改
HTTPS就是HTTP加上加密处理(一般是SSL安全通信线路)+认证+完整性保护
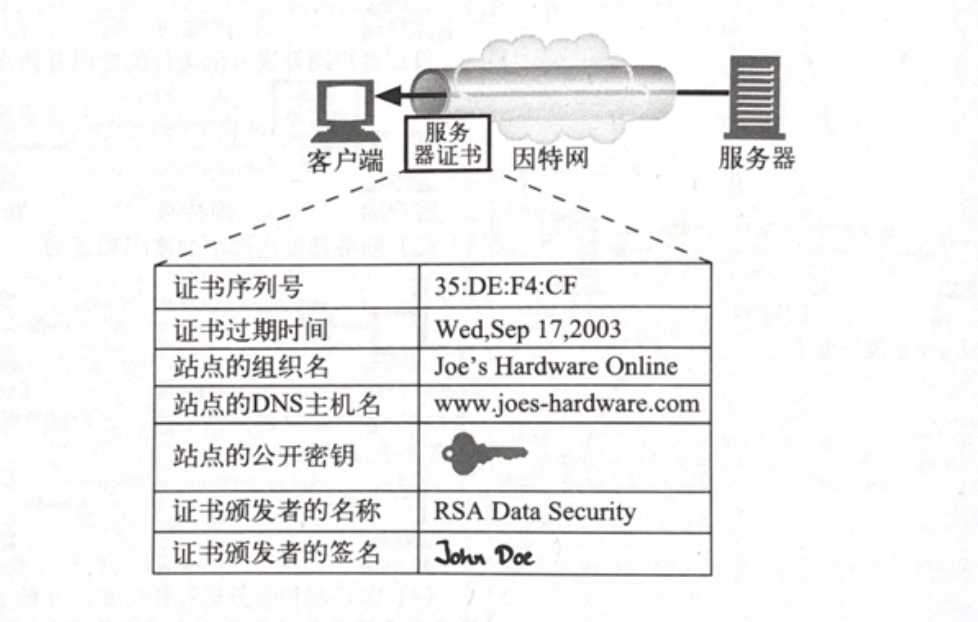
证书内容包括:
- 证书序列号
- 证书过期时间
- 证书颁发者的名称
- 证书颁发者的签名
- 站点的组织名
- 站点的DNS主机名
- 站点的公开密钥
浏览器如何验证服务器数字证书?
- 验证是否在有效期内:已过去 或者 未激活
- 签名颁发者的可信度:每个证书都是由某些证书颁发机构(CA)签发的。浏览器会附带一个 签名颁发机构的授信列表
- 签名检测:获取到公开密钥
- 站点身份检测:因有些服务器会盗用其他证书,所以要验证证书中主机名是否与发送过来的服务器匹配
证书包含信息
端口号
端口,是指TCP/IP协议中的端口,端口号的范围从0到65535,比如用于浏览网页服务的80端口,用于FTP服务的21端口等等
端口号的作用
端口号就是为了区分同一计算机上的不同进程
区分服务,在一个服务器上启动多个服务
不同版本HTTP对比
HTTP1.0 HTTP1.1 HTTP2.0 区别
HTTP1.0 HTTP1.1 区别
* 缓存处理:在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略
* 节约带宽:HTTP1.1支持断点续传。HTTP 1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,否则返回401。客户端如果接受到100,才开始把请求body发送到服务器。HTTP1.1则在请求头引入了range头域
* HOST域:HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
* 长连接:在HTTP1.1中默认开启Connection: keep-alive,支持一次建立TCP发送多个http请求。
* 增加状态码:比如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
HTTP1.1 HTTP2.0 区别
* 多路复用:HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。HTTP1.1也可以建立多次TCP请求,但毕竟需要开销。
* 数据压缩:HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
* 服务器推送:意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
HTTP2.0 header如何压缩
头部压缩需要的支持HTTP/2的浏览器和服务端之间:
- 维护一份相同的静态字典,包含常见的头部名称,以及特别常见的头部名称与值的结合
- 维护一份相同的动态字典,可以动态添加内容
- 支持基于静态哈夫曼码表的哈夫曼编码
请求头
请求头
|
|
HTTP优化
- 利用负载均衡优化和加速HTTP应用
- 利用HTTP Cache来优化网
消息推送
Web应用从服务器主动推送Data到客户端有哪些方式?
- HTML5提供的WebSocket
服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。
|
|
readyState属性返回实例对象的当前状态,共有四种。
- CONNECTING:值为0,表示正在连接。
- OPEN:值为1,表示连接成功,可以通信了。
- CLOSING:值为2,表示连接正在关闭。
- CLOSED:值为3,表示连接已经关闭,或者打开连接失败。
下面是一个示例。
|
|
参考: WebSocket | MDN
其他推送方法
- 不可见的iframe
- WebSocket通过Flash
- XHR长时间连接
- XHR Multipart Streaming
<script>标签的长时间连接(可跨域)
cookie
cookie是存在哪一部分?
请求头。
个人理解:我们请求页面的时候,后端返回的响应头里如果有
Set-Cookie的话,浏览器会自动在缓存里设置这个cookie,当我们下次访问的这个域的时候,就会自动带上这个cookie。比如自动登录,后端返回在请求头token,浏览器就会写在缓存。但当我们访问一个从来没访问过的页面时,就不会带上cookie去访问这个页面,也没有默认cookie可言。
cookie和session的区别
- cookie机制采用的是在客户端保持状态的方案
- session机制采用的是在服务器端保持状态的方案。
(abigale: session是后端识别用户的一个方案,比如当A用户访问我某网站,网站服务器会在set-cookie返回一个session.XXX,当下次用户再访问时,浏览器会将它的cookie带过来,服务器就能识别哪个用户访问了。)
三次握手和四次挥手
三次握手
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手
四次挥手的过程如下:
- 客户端A上的某个进程,主动关闭连接,发送FIN(seq = u)报文给B,然后进入FIN_WAIT_1状态;
- B收到FIN报文,回应一个ACK (ACK = u + 1)报文,进入CLOSED_WAIT状态;A收到FIN报文,进入FIN_WAIT_2状态;
- B向A发送FIN(seq = v)报文,进入LAST_ACK状态;
- A收到FIN报文后,向B发送ACK(ACK = v + 1)报文,进入TIME_WAIT状态
四次挥手后,A和B成功地断开了连接
HTTP包
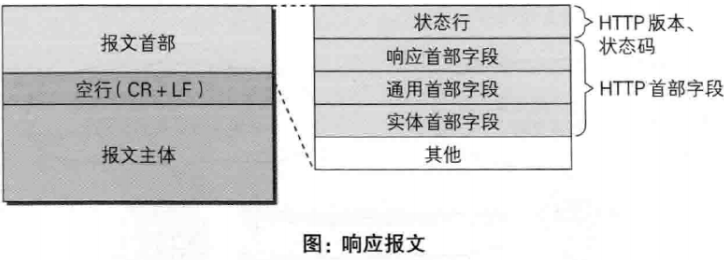
一个响应包
|
|
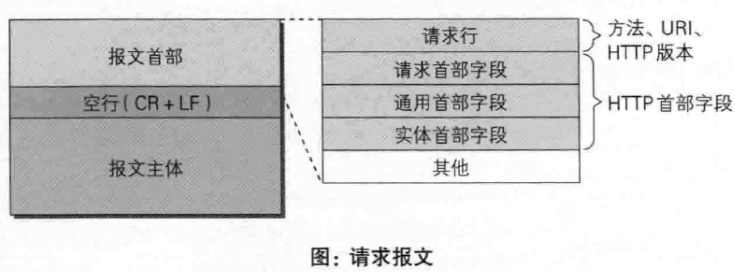
一个请求包
|
|
RESTful
表现层状态转化
- 表现层: 资源
- 状态转化:一个过程,
API定制
- 统一资源接口:GET,DELETE,PUT和POST
- 资源的表述:html、xml、json 在Content-Type中设定
- 以什么方式传参,以什么方式接收参数
- URL中路径的设定:比如按类型划分
- 登录相关的 security
- 查看某某学院 school
- 查看某某学院的某个专业 school/computer
报文
HTTP请求报文与响应报文格式
请求报文包含四部分:
- 请求行:包含请求方法、URI、HTTP版本信息
- 请求首部字段
- 请求内容实体
- 空行
响应报文包含四部分:
- 状态行:包含HTTP版本、状态码、状态码的原因短语
- 响应首部字段
- 响应内容实体
- 空行
常见的首部:
通用首部字段(请求报文与响应报文都会使用的首部字段)
- Date:创建报文时间
- Connection:连接的管理
- Cache-Control:缓存的控制
- Transfer-Encoding:报文主体的传输编码方式
请求首部字段(请求报文会使用的首部字段)
- Host:请求资源所在服务器
- Accept:可处理的媒体类型
- Accept-Charset:可接收的字符集
- Accept-Encoding:可接受的内容编码
- Accept-Language:可接受的自然语言
响应首部字段(响应报文会使用的首部字段)
- Accept-Ranges:可接受的字节范围
- Location:令客户端重新定向到的URI
- Server:HTTP服务器的安装信息
实体首部字段(请求报文与响应报文的的实体部分使用的首部字段)
- Allow:资源可支持的HTTP方法
- Content-Type:实体主类的类型
- Content-Encoding:实体主体适用的编码方式
- Content-Language:实体主体的自然语言
- Content-Length:实体主体的的字节数
- Content-Range:实体主体的位置范围,一般用于发出部分请求时使用
请求报文头
响应报文头