数据结构
栈
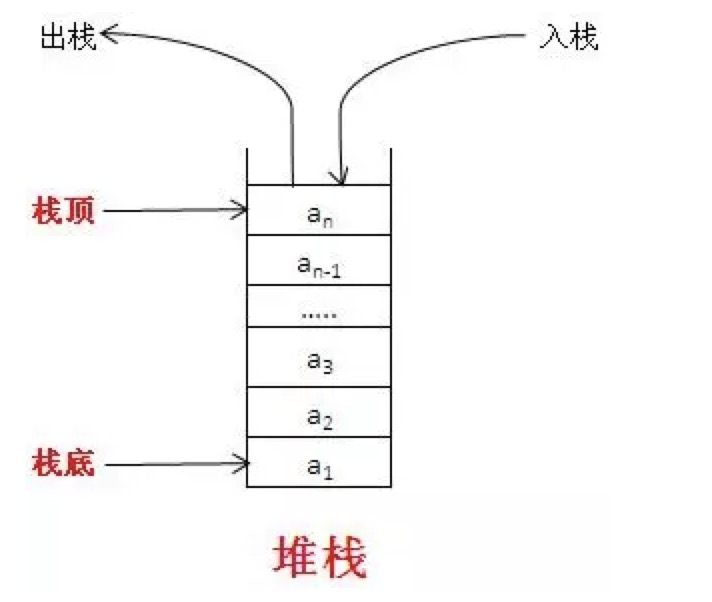
栈是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端称为栈顶。想象一下,我们平常在饭馆见到的一摞盘子就是现实世界常见的栈的例子,只能从最上面取盘子,盘子洗干净后,也只能放在最上面。栈被称为一种后入先出的数据结构。是一种高效的数据结构,因为数据只能在栈顶添加或删除,所以这样的操作很快。 使用条件:
只要数据的保存满足后入先出或先进后出的原理,都优先考虑使用栈
|
|
队列
队列也是一种列表,不同的是队列只能在队尾插入元素,在队首删除元素。想象一下,我们在银行排队,排在最前面的人第一个办理业务,而后面来的人只能排在队伍的后面,直到轮到他们为止。 使用条件:
只要数据的保存满足先进先出、后入后出的原理,都优先考虑使用队列
常见应用场景:
队列主要用在和时间有关的地方,特别是操作系统中,队列是实现多任务的重要机制
消息机制可以通过队列来实现,进程调度也是使用队列来实现

|
|
链表
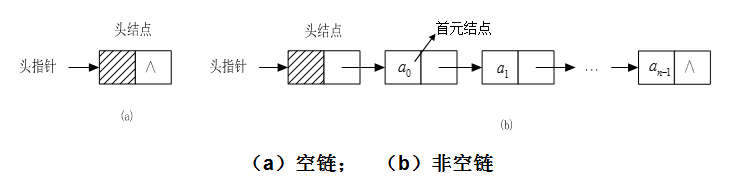
链表也是一种列表,为什么需要出现链表,JavaScript中数组的主要问题时,它们被实现成了对象,与其他语言(比如C++和Java)的数组相对,效率很低。如果你发现数组在实际使用时很慢,就可以考虑使用链表来代替它。 使用条件:
链表几乎可以用在任何可以使用一维数组的情况中。如果需要随机访问,数组仍然是更好的选择。
二叉树和二叉查找树
- 树是计算机科学中经常用到的一种数据结构。
- 树是一种非线性的数据结构,以分层的方式存储数据。
- 二叉树每个节点的子节点不允许超过两个。一个父节点的两个子节点分别称为左节点和右节点,通过将子节点的个数限定为2,可以写出高效的程序在树中插入、查找和删除数据。
- 二叉查找树(BST)是一种特殊的二叉树,相对较小的值保存在左节点中,较大的值保存在右节点中。这一特性使得查找的效率很高,对于数值型和非数值型的数据,比如单词和字符串,都是如此。
二叉查找树实现方法
|
|
时间复杂度
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数f(n),算法的时间度量记为 T(n) = O(f(n)) ,它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同,称作算法的渐近时间复杂度,简称时间复杂度。这里需要重点理解这个增长率。
举个例子,看下面3个代码:
1、{++x;}
2、for(i = 1; i <= n; i++) { ++x; }
3、for(j = 1; j <= n; j++)
for(j = 1; j <= n; j++)
{ ++x; }
上述含有 ++x 操作的语句的频度分别为1 、n 、n^2,
假设问题的规模扩大了n倍,3个代码的增长率分别是1 、n 、n^2
它们的时间复杂度分别为O(1)、O(n )、O(n^2)
二分查找
- 二分查找的时间复杂度为O(logn)
规则
- 定义最小索引和最大索引
- 计算出中间索引
- 拿中间的索引和要查找元素的索引进行比较
- 相等:就返回当前的中间索引
- 不相等:
- 如果大了:在左边查找,max = min - 1
- 如果小了:在右边查找,min = min + 1
|
|
排序
|
|
冒泡
- 从第一个数字开始,依次往后对比,直到最后一位,当该数字大于/小于查找位置上数字时,交换数字
- 重新一轮开始时,对比直到倒数第二位
|
|
选择排序
- 与冒泡相似
- 从第一位开始,依次对比找到最小那一位,存下下标,与第一位做交换
- 从第二位开始,再次找最小那一位
|
|
插入排序
- 将组分成“已排序”和“未排序”
- 从第一位开始,依次从“未排序”获取一位,再对“已排序”列表进行排序
|
|
归并排序/分治法
|
|
快速排序
取中间值,然后不断比较左右两边的数组
|
|